Program schedules can be used as evaluation logic models. Making this linkage provides two benefits. One is a stronger connection between program managers and evaluators. Do a thought experiment: how many program managers would be upset if the evaluation logic model for their program vanished? Compare the answer with the number that would be upset if their program plans and schedules disappeared. Because managers care so much about plans and schedules, treating those schedules as logic models forges a bond between program management and evaluation.
The second benefit is that using program plans as evaluation models can provide useful knowledge that would not otherwise be revealed. That knowledge comes from the “activity / time / milestone” relationships that are not usually a framing factor in evaluation design.
I made this argument before in an AJE article. My purpose here is to resurface this idea and invite comment.
To get an idea of what I have in mind, see Figure 1. It is a highly simplified example drawn from an evaluation of a program to reduce distracted driving. The actual model was a lot more elaborate, but this simplified version works best to explain what I am advocating.
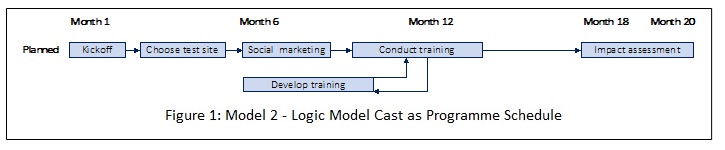
Compare Figure 1 with a morphologically identical model, but this time cast as a traditional logic model.
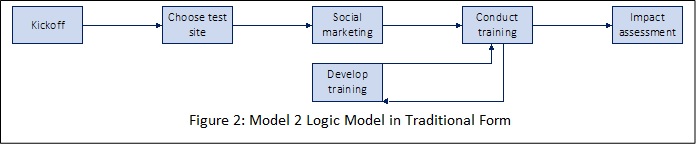
What special insight might come from Model 1 that is not evident in Model 2? The answer is shown in Figure 3, which compares the actual with the lived schedule, and then layers on a data collection timeline and a methodology.
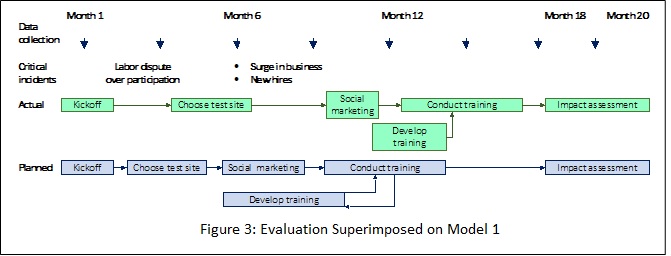
What is evident in the schedule-based model?
- There was a delay from the time of kickoff to choosing a test site.
- There was a delay between choosing a test site and beginning the social marketing needed to gain acceptance to implement the program.
- Training development started late, had less time to develop and test curriculum, and was done more in parallel with training delivery than was planned.
- There was less time between training and impact assessment.
All these behaviors are consequential.
- Even if we did not know why, we have learned that settings like this may be prone to unexpected delays in startup activities.
- If the training was successful, we would know that high quality training can be attained with less time and more simultaneity with training delivery than we thought possible. If training was not adequate, we would have a hint as to what went wrong.
- Impact assessment took place much sooner after training than had been planned. Presumably, the original lag had been built in because the stakeholders had specific beliefs about the need for impact over time. As things turned out, we can tell stakeholders whether the training was effective, but we cannot tell them if the effect lasted.
Of course, all these program behaviors might have been observed and studied even if a traditional logic model had been used. But I think that there are two reasons why this is unlikely. One reason touches on insight that comes from the visual display of information. The other deals with methodology.
Visual: Because timing is a critical element in Model 1, the visuals facilitate attention to when activities begin, end, and overlap. Theories of program action are embedded in those relationships, and, thus, changes in those relationships speak to beliefs about what makes a program succeed.
There may be evaluators who have the inspiration needed to attend to these relationships even if they were only working with Model 2. But I am not one of them, and I bet that most evaluators are not either.
Methodology: The methodology I used is depicted in the top three lines in Figure 3 – time, data collection, and analysis method.
Data were collected at regular intervals, not synchronized to the schedule. There are several reasons for calendar driven data collection. One is that it’s not always obvious that a schedule slip is consequential. Sometimes the importance of a schedule change can only be determined in retrospect. Second, changes in timing for activities are not always reflected in formal plans. An evaluator may have to construct (or at least fill in) a more well-defined plan then managers may use. Further, regular data collection reduces the burden on managers. They do not have to tell the evaluator when there is a change. The evaluator can find that out for him or herself.
As for why schedules change, I have found that using a critical incident technique works well. In addition to using critical incidents, the schedule configuration provides guidance for data interpretation. For instance, Figure 3 shows an unexpected relationship between training development and training delivery. It also shows a shorter time between training and impact assessment. Neither of these changes affect what data are collected and how the data are analyzed, but it does have implications for data interpretation.
Jonathan (Jonny) Morell